Comprehensive AI research skill library for autonomous research workflows, model training, evaluation, inference, MLOps, RAG, multimodal systems, and paper writing.
Skills(98)
autoresearch—Orchestrates end-to-end autonomous AI research projects using a two-loop architecture. The inner loop runs rapid experiment iterations with clear optimization targets. The outer loop synthesizes results, identifies patterns, and steers research direction. Routes to domain-specific skills for execution, supports continuous agent operation via Claude Code /loop and OpenClaw heartbeat, and produces research presentations and papers. Use when starting a research project, running autonomous experiments, or managing a multi-hypothesis research effort.
implementing-llms-litgpt—Implements and trains LLMs using Lightning AI's LitGPT with 20+ pretrained architectures (Llama, Gemma, Phi, Qwen, Mistral). Use when need clean model implementations, educational understanding of architectures, or production fine-tuning with LoRA/QLoRA. Single-file implementations, no abstraction layers.
mamba-architecture—State-space model with O(n) complexity vs Transformers' O(n²). 5× faster inference, million-token sequences, no KV cache. Selective SSM with hardware-aware design. Mamba-1 (d_state=16) and Mamba-2 (d_state=128, multi-head). Models 130M-2.8B on HuggingFace.
nanogpt—Educational GPT implementation in ~300 lines. Reproduces GPT-2 (124M) on OpenWebText. Clean, hackable code for learning transformers. By Andrej Karpathy. Perfect for understanding GPT architecture from scratch. Train on Shakespeare (CPU) or OpenWebText (multi-GPU).
rwkv-architecture—RNN+Transformer hybrid with O(n) inference. Linear time, infinite context, no KV cache. Train like GPT (parallel), infer like RNN (sequential). Linux Foundation AI project. Production at Windows, Office, NeMo. RWKV-7 (March 2025). Models up to 14B parameters.
distributed-llm-pretraining-torchtitan—Provides PyTorch-native distributed LLM pretraining using torchtitan with 4D parallelism (FSDP2, TP, PP, CP). Use when pretraining Llama 3.1, DeepSeek V3, or custom models at scale from 8 to 512+ GPUs with Float8, torch.compile, and distributed checkpointing.
huggingface-tokenizers—Fast tokenizers optimized for research and production. Rust-based implementation tokenizes 1GB in <20 seconds. Supports BPE, WordPiece, and Unigram algorithms. Train custom vocabularies, track alignments, handle padding/truncation. Integrates seamlessly with transformers. Use when you need high-performance tokenization or custom tokenizer training.
sentencepiece—Language-independent tokenizer treating text as raw Unicode. Supports BPE and Unigram algorithms. Fast (50k sentences/sec), lightweight (6MB memory), deterministic vocabulary. Used by T5, ALBERT, XLNet, mBART. Train on raw text without pre-tokenization. Use when you need multilingual support, CJK languages, or reproducible tokenization.
axolotl—Expert guidance for fine-tuning LLMs with Axolotl - YAML configs, 100+ models, LoRA/QLoRA, DPO/KTO/ORPO/GRPO, multimodal support
llama-factory—Expert guidance for fine-tuning LLMs with LLaMA-Factory - WebUI no-code, 100+ models, 2/3/4/5/6/8-bit QLoRA, multimodal support
peft-fine-tuning—Parameter-efficient fine-tuning for LLMs using LoRA, QLoRA, and 25+ methods. Use when fine-tuning large models (7B-70B) with limited GPU memory, when you need to train <1% of parameters with minimal accuracy loss, or for multi-adapter serving. HuggingFace's official library integrated with transformers ecosystem.
unsloth—Expert guidance for fast fine-tuning with Unsloth - 2-5x faster training, 50-80% less memory, LoRA/QLoRA optimization
nnsight-remote-interpretability—Provides guidance for interpreting and manipulating neural network internals using nnsight with optional NDIF remote execution. Use when needing to run interpretability experiments on massive models (70B+) without local GPU resources, or when working with any PyTorch architecture.
pyvene-interventions—Provides guidance for performing causal interventions on PyTorch models using pyvene's declarative intervention framework. Use when conducting causal tracing, activation patching, interchange intervention training, or testing causal hypotheses about model behavior.
sparse-autoencoder-training—Provides guidance for training and analyzing Sparse Autoencoders (SAEs) using SAELens to decompose neural network activations into interpretable features. Use when discovering interpretable features, analyzing superposition, or studying monosemantic representations in language models.
transformer-lens-interpretability—Provides guidance for mechanistic interpretability research using TransformerLens to inspect and manipulate transformer internals via HookPoints and activation caching. Use when reverse-engineering model algorithms, studying attention patterns, or performing activation patching experiments.
nemo-curator—GPU-accelerated data curation for LLM training. Supports text/image/video/audio. Features fuzzy deduplication (16× faster), quality filtering (30+ heuristics), semantic deduplication, PII redaction, NSFW detection. Scales across GPUs with RAPIDS. Use for preparing high-quality training datasets, cleaning web data, or deduplicating large corpora.
ray-data—Scalable data processing for ML workloads. Streaming execution across CPU/GPU, supports Parquet/CSV/JSON/images. Integrates with Ray Train, PyTorch, TensorFlow. Scales from single machine to 100s of nodes. Use for batch inference, data preprocessing, multi-modal data loading, or distributed ETL pipelines.
grpo-rl-training—Expert guidance for GRPO/RL fine-tuning with TRL for reasoning and task-specific model training
miles-rl-training—Provides guidance for enterprise-grade RL training using miles, a production-ready fork of slime. Use when training large MoE models with FP8/INT4, needing train-inference alignment, or requiring speculative RL for maximum throughput.
openrlhf-training—High-performance RLHF framework with Ray+vLLM acceleration. Use for PPO, GRPO, RLOO, DPO training of large models (7B-70B+). Built on Ray, vLLM, ZeRO-3. 2× faster than DeepSpeedChat with distributed architecture and GPU resource sharing.
simpo-training—Simple Preference Optimization for LLM alignment. Reference-free alternative to DPO with better performance (+6.4 points on AlpacaEval 2.0). No reference model needed, more efficient than DPO. Use for preference alignment when want simpler, faster training than DPO/PPO.
slime-rl-training—Provides guidance for LLM post-training with RL using slime, a Megatron+SGLang framework. Use when training GLM models, implementing custom data generation workflows, or needing tight Megatron-LM integration for RL scaling.
torchforge-rl-training—Provides guidance for PyTorch-native agentic RL using torchforge, Meta's library separating infra from algorithms. Use when you want clean RL abstractions, easy algorithm experimentation, or scalable training with Monarch and TorchTitan.
fine-tuning-with-trl—Fine-tune LLMs using reinforcement learning with TRL - SFT for instruction tuning, DPO for preference alignment, PPO/GRPO for reward optimization, and reward model training. Use when need RLHF, align model with preferences, or train from human feedback. Works with HuggingFace Transformers.
verl-rl-training—Provides guidance for training LLMs with reinforcement learning using verl (Volcano Engine RL). Use when implementing RLHF, GRPO, PPO, or other RL algorithms for LLM post-training at scale with flexible infrastructure backends.
constitutional-ai—Anthropic's method for training harmless AI through self-improvement. Two-phase approach - supervised learning with self-critique/revision, then RLAIF (RL from AI Feedback). Use for safety alignment, reducing harmful outputs without human labels. Powers Claude's safety system.
llamaguard—Meta's 7-8B specialized moderation model for LLM input/output filtering. 6 safety categories - violence/hate, sexual content, weapons, substances, self-harm, criminal planning. 94-95% accuracy. Deploy with vLLM, HuggingFace, Sagemaker. Integrates with NeMo Guardrails.
nemo-guardrails—NVIDIA's runtime safety framework for LLM applications. Features jailbreak detection, input/output validation, fact-checking, hallucination detection, PII filtering, toxicity detection. Uses Colang 2.0 DSL for programmable rails. Production-ready, runs on T4 GPU.
prompt-guard—Meta's 86M prompt injection and jailbreak detector. Filters malicious prompts and third-party data for LLM apps. 99%+ TPR, <1% FPR. Fast (<2ms GPU). Multilingual (8 languages). Deploy with HuggingFace or batch processing for RAG security.
huggingface-accelerate—Simplest distributed training API. 4 lines to add distributed support to any PyTorch script. Unified API for DeepSpeed/FSDP/Megatron/DDP. Automatic device placement, mixed precision (FP16/BF16/FP8). Interactive config, single launch command. HuggingFace ecosystem standard.
deepspeed—Expert guidance for distributed training with DeepSpeed - ZeRO optimization stages, pipeline parallelism, FP16/BF16/FP8, 1-bit Adam, sparse attention
training-llms-megatron—Trains large language models (2B-462B parameters) using NVIDIA Megatron-Core with advanced parallelism strategies. Use when training models >1B parameters, need maximum GPU efficiency (47% MFU on H100), or require tensor/pipeline/sequence/context/expert parallelism. Production-ready framework used for Nemotron, LLaMA, DeepSeek.
pytorch-fsdp2—Adds PyTorch FSDP2 (fully_shard) to training scripts with correct init, sharding, mixed precision/offload config, and distributed checkpointing. Use when models exceed single-GPU memory or when you need DTensor-based sharding with DeviceMesh.
pytorch-lightning—High-level PyTorch framework with Trainer class, automatic distributed training (DDP/FSDP/DeepSpeed), callbacks system, and minimal boilerplate. Scales from laptop to supercomputer with same code. Use when you want clean training loops with built-in best practices.
ray-train—Distributed training orchestration across clusters. Scales PyTorch/TensorFlow/HuggingFace from laptop to 1000s of nodes. Built-in hyperparameter tuning with Ray Tune, fault tolerance, elastic scaling. Use when training massive models across multiple machines or running distributed hyperparameter sweeps.
lambda-labs-gpu-cloud—Reserved and on-demand GPU cloud instances for ML training and inference. Use when you need dedicated GPU instances with simple SSH access, persistent filesystems, or high-performance multi-node clusters for large-scale training.
modal-serverless-gpu—Serverless GPU cloud platform for running ML workloads. Use when you need on-demand GPU access without infrastructure management, deploying ML models as APIs, or running batch jobs with automatic scaling.
skypilot-multi-cloud-orchestration—Multi-cloud orchestration for ML workloads with automatic cost optimization. Use when you need to run training or batch jobs across multiple clouds, leverage spot instances with auto-recovery, or optimize GPU costs across providers.
awq-quantization—Activation-aware weight quantization for 4-bit LLM compression with 3x speedup and minimal accuracy loss. Use when deploying large models (7B-70B) on limited GPU memory, when you need faster inference than GPTQ with better accuracy preservation, or for instruction-tuned and multimodal models. MLSys 2024 Best Paper Award winner.
quantizing-models-bitsandbytes—Quantizes LLMs to 8-bit or 4-bit for 50-75% memory reduction with minimal accuracy loss. Use when GPU memory is limited, need to fit larger models, or want faster inference. Supports INT8, NF4, FP4 formats, QLoRA training, and 8-bit optimizers. Works with HuggingFace Transformers.
optimizing-attention-flash—Optimizes transformer attention with Flash Attention for 2-4x speedup and 10-20x memory reduction. Use when training/running transformers with long sequences (>512 tokens), encountering GPU memory issues with attention, or need faster inference. Supports PyTorch native SDPA, flash-attn library, H100 FP8, and sliding window attention.
gguf-quantization—GGUF format and llama.cpp quantization for efficient CPU/GPU inference. Use when deploying models on consumer hardware, Apple Silicon, or when needing flexible quantization from 2-8 bit without GPU requirements.
gptq—Post-training 4-bit quantization for LLMs with minimal accuracy loss. Use for deploying large models (70B, 405B) on consumer GPUs, when you need 4× memory reduction with <2% perplexity degradation, or for faster inference (3-4× speedup) vs FP16. Integrates with transformers and PEFT for QLoRA fine-tuning.
hqq-quantization—Half-Quadratic Quantization for LLMs without calibration data. Use when quantizing models to 4/3/2-bit precision without needing calibration datasets, for fast quantization workflows, or when deploying with vLLM or HuggingFace Transformers.
ml-training-recipes—Battle-tested PyTorch training recipes for all domains — LLMs, vision, diffusion, medical imaging, protein/drug discovery, spatial omics, genomics. Covers training loops, optimizer selection (AdamW, Muon), LR scheduling, mixed precision, debugging, and systematic experimentation. Use when training or fine-tuning neural networks, debugging loss spikes or OOM, choosing architectures, or optimizing GPU throughput.
evaluating-code-models—Evaluates code generation models across HumanEval, MBPP, MultiPL-E, and 15+ benchmarks with pass@k metrics. Use when benchmarking code models, comparing coding abilities, testing multi-language support, or measuring code generation quality. Industry standard from BigCode Project used by HuggingFace leaderboards.
evaluating-llms-harness—Evaluates LLMs across 60+ academic benchmarks (MMLU, HumanEval, GSM8K, TruthfulQA, HellaSwag). Use when benchmarking model quality, comparing models, reporting academic results, or tracking training progress. Industry standard used by EleutherAI, HuggingFace, and major labs. Supports HuggingFace, vLLM, APIs.
nemo-evaluator-sdk—Evaluates LLMs across 100+ benchmarks from 18+ harnesses (MMLU, HumanEval, GSM8K, safety, VLM) with multi-backend execution. Use when needing scalable evaluation on local Docker, Slurm HPC, or cloud platforms. NVIDIA's enterprise-grade platform with container-first architecture for reproducible benchmarking.
llama-cpp—Runs LLM inference on CPU, Apple Silicon, and consumer GPUs without NVIDIA hardware. Use for edge deployment, M1/M2/M3 Macs, AMD/Intel GPUs, or when CUDA is unavailable. Supports GGUF quantization (1.5-8 bit) for reduced memory and 4-10× speedup vs PyTorch on CPU.
sglang—Fast structured generation and serving for LLMs with RadixAttention prefix caching. Use for JSON/regex outputs, constrained decoding, agentic workflows with tool calls, or when you need 5× faster inference than vLLM with prefix sharing. Powers 300,000+ GPUs at xAI, AMD, NVIDIA, and LinkedIn.
tensorrt-llm—Optimizes LLM inference with NVIDIA TensorRT for maximum throughput and lowest latency. Use for production deployment on NVIDIA GPUs (A100/H100), when you need 10-100x faster inference than PyTorch, or for serving models with quantization (FP8/INT4), in-flight batching, and multi-GPU scaling.
serving-llms-vllm—Serves LLMs with high throughput using vLLM's PagedAttention and continuous batching. Use when deploying production LLM APIs, optimizing inference latency/throughput, or serving models with limited GPU memory. Supports OpenAI-compatible endpoints, quantization (GPTQ/AWQ/FP8), and tensor parallelism.
mlflow—Track ML experiments, manage model registry with versioning, deploy models to production, and reproduce experiments with MLflow - framework-agnostic ML lifecycle platform
experiment-tracking-swanlab—Provides guidance for experiment tracking with SwanLab. Use when you need open-source run tracking, local or self-hosted dashboards, and lightweight media logging for ML workflows.
tensorboard—Visualize training metrics, debug models with histograms, compare experiments, visualize model graphs, and profile performance with TensorBoard - Google's ML visualization toolkit
weights-and-biases—Track ML experiments with automatic logging, visualize training in real-time, optimize hyperparameters with sweeps, and manage model registry with W&B - collaborative MLOps platform
evolving-ai-agents—Provides guidance for automatically evolving and optimizing AI agents across any domain using LLM-driven evolution algorithms. Use when building self-improving agents, optimizing agent prompts and skills against benchmarks, or implementing automated agent evaluation loops.
autogpt-agents—Autonomous AI agent platform for building and deploying continuous agents. Use when creating visual workflow agents, deploying persistent autonomous agents, or building complex multi-step AI automation systems.
crewai-multi-agent—Multi-agent orchestration framework for autonomous AI collaboration. Use when building teams of specialized agents working together on complex tasks, when you need role-based agent collaboration with memory, or for production workflows requiring sequential/hierarchical execution. Built without LangChain dependencies for lean, fast execution.
langchain—Framework for building LLM-powered applications with agents, chains, and RAG. Supports multiple providers (OpenAI, Anthropic, Google), 500+ integrations, ReAct agents, tool calling, memory management, and vector store retrieval. Use for building chatbots, question-answering systems, autonomous agents, or RAG applications. Best for rapid prototyping and production deployments.
llamaindex—Data framework for building LLM applications with RAG. Specializes in document ingestion (300+ connectors), indexing, and querying. Features vector indices, query engines, agents, and multi-modal support. Use for document Q&A, chatbots, knowledge retrieval, or building RAG pipelines. Best for data-centric LLM applications.
chroma—Open-source embedding database for AI applications. Store embeddings and metadata, perform vector and full-text search, filter by metadata. Simple 4-function API. Scales from notebooks to production clusters. Use for semantic search, RAG applications, or document retrieval. Best for local development and open-source projects.
faiss—Facebook's library for efficient similarity search and clustering of dense vectors. Supports billions of vectors, GPU acceleration, and various index types (Flat, IVF, HNSW). Use for fast k-NN search, large-scale vector retrieval, or when you need pure similarity search without metadata. Best for high-performance applications.
pinecone—Managed vector database for production AI applications. Fully managed, auto-scaling, with hybrid search (dense + sparse), metadata filtering, and namespaces. Low latency (<100ms p95). Use for production RAG, recommendation systems, or semantic search at scale. Best for serverless, managed infrastructure.
qdrant-vector-search—High-performance vector similarity search engine for RAG and semantic search. Use when building production RAG systems requiring fast nearest neighbor search, hybrid search with filtering, or scalable vector storage with Rust-powered performance.
sentence-transformers—Framework for state-of-the-art sentence, text, and image embeddings. Provides 5000+ pre-trained models for semantic similarity, clustering, and retrieval. Supports multilingual, domain-specific, and multimodal models. Use for generating embeddings for RAG, semantic search, or similarity tasks. Best for production embedding generation.
dspy—Build complex AI systems with declarative programming, optimize prompts automatically, create modular RAG systems and agents with DSPy - Stanford NLP's framework for systematic LM programming
guidance—Control LLM output with regex and grammars, guarantee valid JSON/XML/code generation, enforce structured formats, and build multi-step workflows with Guidance - Microsoft Research's constrained generation framework
instructor—Extract structured data from LLM responses with Pydantic validation, retry failed extractions automatically, parse complex JSON with type safety, and stream partial results with Instructor - battle-tested structured output library
outlines—Guarantee valid JSON/XML/code structure during generation, use Pydantic models for type-safe outputs, support local models (Transformers, vLLM), and maximize inference speed with Outlines - dottxt.ai's structured generation library
langsmith-observability—LLM observability platform for tracing, evaluation, and monitoring. Use when debugging LLM applications, evaluating model outputs against datasets, monitoring production systems, or building systematic testing pipelines for AI applications.
phoenix-observability—Open-source AI observability platform for LLM tracing, evaluation, and monitoring. Use when debugging LLM applications with detailed traces, running evaluations on datasets, or monitoring production AI systems with real-time insights.
audiocraft-audio-generation—PyTorch library for audio generation including text-to-music (MusicGen) and text-to-sound (AudioGen). Use when you need to generate music from text descriptions, create sound effects, or perform melody-conditioned music generation.
blip-2-vision-language—Vision-language pre-training framework bridging frozen image encoders and LLMs. Use when you need image captioning, visual question answering, image-text retrieval, or multimodal chat with state-of-the-art zero-shot performance.
clip—OpenAI's model connecting vision and language. Enables zero-shot image classification, image-text matching, and cross-modal retrieval. Trained on 400M image-text pairs. Use for image search, content moderation, or vision-language tasks without fine-tuning. Best for general-purpose image understanding.
evaluating-cosmos-policy—Evaluates NVIDIA Cosmos Policy on LIBERO and RoboCasa simulation environments. Use when setting up cosmos-policy for robot manipulation evaluation, running headless GPU evaluations with EGL rendering, or profiling inference latency on cluster or local GPU machines.
llava—Large Language and Vision Assistant. Enables visual instruction tuning and image-based conversations. Combines CLIP vision encoder with Vicuna/LLaMA language models. Supports multi-turn image chat, visual question answering, and instruction following. Use for vision-language chatbots or image understanding tasks. Best for conversational image analysis.
fine-tuning-serving-openpi—Fine-tune and serve Physical Intelligence OpenPI models (pi0, pi0-fast, pi0.5) using JAX or PyTorch backends for robot policy inference across ALOHA, DROID, and LIBERO environments. Use when adapting pi0 models to custom datasets, converting JAX checkpoints to PyTorch, running policy inference servers, or debugging norm stats and GPU memory issues.
fine-tuning-openvla-oft—Fine-tunes and evaluates OpenVLA-OFT and OpenVLA-OFT+ policies for robot action generation with continuous action heads, LoRA adaptation, and FiLM conditioning on LIBERO simulation and ALOHA real-world setups. Use when reproducing OpenVLA-OFT paper results, training custom VLA action heads (L1 or diffusion), deploying server-client inference for ALOHA, or debugging normalization, LoRA merge, and cross-GPU issues.
segment-anything-model—Foundation model for image segmentation with zero-shot transfer. Use when you need to segment any object in images using points, boxes, or masks as prompts, or automatically generate all object masks in an image.
stable-diffusion-image-generation—State-of-the-art text-to-image generation with Stable Diffusion models via HuggingFace Diffusers. Use when generating images from text prompts, performing image-to-image translation, inpainting, or building custom diffusion pipelines.
whisper—OpenAI's general-purpose speech recognition model. Supports 99 languages, transcription, translation to English, and language identification. Six model sizes from tiny (39M params) to large (1550M params). Use for speech-to-text, podcast transcription, or multilingual audio processing. Best for robust, multilingual ASR.
knowledge-distillation—Compress large language models using knowledge distillation from teacher to student models. Use when deploying smaller models with retained performance, transferring GPT-4 capabilities to open-source models, or reducing inference costs. Covers temperature scaling, soft targets, reverse KLD, logit distillation, and MiniLLM training strategies.
long-context—Extend context windows of transformer models using RoPE, YaRN, ALiBi, and position interpolation techniques. Use when processing long documents (32k-128k+ tokens), extending pre-trained models beyond original context limits, or implementing efficient positional encodings. Covers rotary embeddings, attention biases, interpolation methods, and extrapolation strategies for LLMs.
model-merging—Merge multiple fine-tuned models using mergekit to combine capabilities without retraining. Use when creating specialized models by blending domain-specific expertise (math + coding + chat), improving performance beyond single models, or experimenting rapidly with model variants. Covers SLERP, TIES-Merging, DARE, Task Arithmetic, linear merging, and production deployment strategies.
model-pruning—Reduce LLM size and accelerate inference using pruning techniques like Wanda and SparseGPT. Use when compressing models without retraining, achieving 50% sparsity with minimal accuracy loss, or enabling faster inference on hardware accelerators. Covers unstructured pruning, structured pruning, N:M sparsity, magnitude pruning, and one-shot methods.
moe-training—Train Mixture of Experts (MoE) models using DeepSpeed or HuggingFace. Use when training large-scale models with limited compute (5× cost reduction vs dense models), implementing sparse architectures like Mixtral 8x7B or DeepSeek-V3, or scaling model capacity without proportional compute increase. Covers MoE architectures, routing mechanisms, load balancing, expert parallelism, and inference optimization.
speculative-decoding—Accelerate LLM inference using speculative decoding, Medusa multiple heads, and lookahead decoding techniques. Use when optimizing inference speed (1.5-3.6× speedup), reducing latency for real-time applications, or deploying models with limited compute. Covers draft models, tree-based attention, Jacobi iteration, parallel token generation, and production deployment strategies.
academic-plotting—Generates publication-quality figures for ML papers from research context. Given a paper section or description, extracts system components and relationships to generate architecture diagrams via Gemini. Given experiment results or data, auto-selects chart type and generates data-driven figures via matplotlib/seaborn. Use when creating any figure for a conference paper.
ml-paper-writing—Write publication-ready ML/AI papers for NeurIPS, ICML, ICLR, ACL, AAAI, COLM. Use when drafting papers from research repos, structuring arguments, verifying citations, or preparing camera-ready submissions. For systems venues (OSDI, NSDI, ASPLOS, SOSP), use systems-paper-writing instead.
presenting-conference-talks—Generates conference presentation slides (Beamer LaTeX PDF and editable PPTX) from a compiled paper with speaker notes and talk script. Use when preparing oral talks, spotlight presentations, or invited talks for ML and systems conferences.
systems-paper-writing—Comprehensive guide for writing systems papers targeting OSDI, SOSP, ASPLOS, NSDI, and EuroSys. Provides paragraph-level structural blueprints, writing patterns, venue-specific checklists, reviewer guidelines, LaTeX templates, and conference deadlines. Use this skill for all systems conference paper writing.
brainstorming-research-ideas—Guides researchers through structured ideation frameworks to discover high-impact research directions. Use when exploring new problem spaces, pivoting between projects, or seeking novel angles on existing work.
creative-thinking-for-research—Applies cognitive science frameworks for creative thinking to CS and AI research ideation. Use when seeking genuinely novel research directions by leveraging combinatorial creativity, analogical reasoning, constraint manipulation, and other empirically grounded creative strategies.
ara-compiler—Compiles any research input — PDF papers, GitHub repositories, experiment logs, code directories, or raw notes — into a complete Agent-Native Research Artifact (ARA) with cognitive layer (claims, concepts, heuristics), physical layer (configs, code stubs), exploration graph, and grounded evidence. Use when ingesting a paper or codebase into a structured, machine-executable knowledge package, building an ARA from scratch, or converting research outputs into a falsifiable, agent-traversable form.
ara-research-manager—Records research provenance as a post-task epilogue, scanning conversation history at the end of a coding or research session to extract decisions, experiments, dead ends, claims, heuristics, and pivots, and writing them into the ara/ directory with user-vs-AI provenance tags. Use as a session epilogue — never during execution — to maintain a faithful, auditable trace of how a research project actually evolved.
ara-rigor-reviewer—Performs ARA Seal Level 2 semantic epistemic review on Agent-Native Research Artifacts, scoring six dimensions (evidence relevance, falsifiability, scope calibration, argument coherence, exploration integrity, methodological rigor) and producing a constructive, severity-ranked report with a Strong Accept-to-Reject recommendation. Use after Level 1 structural validation passes, when an ARA needs an objective epistemic critique before publication or release.
Rules(1)
CLAUDE.md—Original Claude Code repository instructions preserved from the source.
README.md
written by forgecat
Orchestra Research AI Research Skills
Comprehensive AI research skill library for autonomous research workflows, model training, evaluation, inference, MLOps, RAG, multimodal systems, and paper writing.
autoresearch — Orchestrates end-to-end autonomous AI research projects using a two-loop architecture. The inner loop runs rapid experiment iterations with clear optimization targets. The outer loop synthesizes results, identifies patterns, and steers research direction. Routes to domain-specific skills for execution, supports continuous agent operation via Claude Code /loop and OpenClaw heartbeat, and produces research presentations and papers. Use when starting a research project, running autonomous experiments, or managing a multi-hypothesis research effort. skill
implementing-llms-litgpt — Implements and trains LLMs using Lightning AI's LitGPT with 20+ pretrained architectures (Llama, Gemma, Phi, Qwen, Mistral). Use when need clean model implementations, educational understanding of architectures, or production fine-tuning with LoRA/QLoRA. Single-file implementations, no abstraction layers. skill
mamba-architecture — State-space model with O(n) complexity vs Transformers' O(n²). 5× faster inference, million-token sequences, no KV cache. Selective SSM with hardware-aware design. Mamba-1 (d_state=16) and Mamba-2 (d_state=128, multi-head). Models 130M-2.8B on HuggingFace. skill
nanogpt — Educational GPT implementation in ~300 lines. Reproduces GPT-2 (124M) on OpenWebText. Clean, hackable code for learning transformers. By Andrej Karpathy. Perfect for understanding GPT architecture from scratch. Train on Shakespeare (CPU) or OpenWebText (multi-GPU). skill
rwkv-architecture — RNN+Transformer hybrid with O(n) inference. Linear time, infinite context, no KV cache. Train like GPT (parallel), infer like RNN (sequential). Linux Foundation AI project. Production at Windows, Office, NeMo. RWKV-7 (March 2025). Models up to 14B parameters. skill
distributed-llm-pretraining-torchtitan — Provides PyTorch-native distributed LLM pretraining using torchtitan with 4D parallelism (FSDP2, TP, PP, CP). Use when pretraining Llama 3.1, DeepSeek V3, or custom models at scale from 8 to 512+ GPUs with Float8, torch.compile, and distributed checkpointing. skill
huggingface-tokenizers — Fast tokenizers optimized for research and production. Rust-based implementation tokenizes 1GB in <20 seconds. Supports BPE, WordPiece, and Unigram algorithms. Train custom vocabularies, track alignments, handle padding/truncation. Integrates seamlessly with transformers. Use when you need high-performance tokenization or custom tokenizer training. skill
sentencepiece — Language-independent tokenizer treating text as raw Unicode. Supports BPE and Unigram algorithms. Fast (50k sentences/sec), lightweight (6MB memory), deterministic vocabulary. Used by T5, ALBERT, XLNet, mBART. Train on raw text without pre-tokenization. Use when you need multilingual support, CJK languages, or reproducible tokenization. skill
axolotl — Expert guidance for fine-tuning LLMs with Axolotl - YAML configs, 100+ models, LoRA/QLoRA, DPO/KTO/ORPO/GRPO, multimodal support skill
llama-factory — Expert guidance for fine-tuning LLMs with LLaMA-Factory - WebUI no-code, 100+ models, 2/3/4/5/6/8-bit QLoRA, multimodal support skill
peft-fine-tuning — Parameter-efficient fine-tuning for LLMs using LoRA, QLoRA, and 25+ methods. Use when fine-tuning large models (7B-70B) with limited GPU memory, when you need to train <1% of parameters with minimal accuracy loss, or for multi-adapter serving. HuggingFace's official library integrated with transformers ecosystem. skill
unsloth — Expert guidance for fast fine-tuning with Unsloth - 2-5x faster training, 50-80% less memory, LoRA/QLoRA optimization skill
nnsight-remote-interpretability — Provides guidance for interpreting and manipulating neural network internals using nnsight with optional NDIF remote execution. Use when needing to run interpretability experiments on massive models (70B+) without local GPU resources, or when working with any PyTorch architecture. skill
pyvene-interventions — Provides guidance for performing causal interventions on PyTorch models using pyvene's declarative intervention framework. Use when conducting causal tracing, activation patching, interchange intervention training, or testing causal hypotheses about model behavior. skill
sparse-autoencoder-training — Provides guidance for training and analyzing Sparse Autoencoders (SAEs) using SAELens to decompose neural network activations into interpretable features. Use when discovering interpretable features, analyzing superposition, or studying monosemantic representations in language models. skill
transformer-lens-interpretability — Provides guidance for mechanistic interpretability research using TransformerLens to inspect and manipulate transformer internals via HookPoints and activation caching. Use when reverse-engineering model algorithms, studying attention patterns, or performing activation patching experiments. skill
nemo-curator — GPU-accelerated data curation for LLM training. Supports text/image/video/audio. Features fuzzy deduplication (16× faster), quality filtering (30+ heuristics), semantic deduplication, PII redaction, NSFW detection. Scales across GPUs with RAPIDS. Use for preparing high-quality training datasets, cleaning web data, or deduplicating large corpora. skill
ray-data — Scalable data processing for ML workloads. Streaming execution across CPU/GPU, supports Parquet/CSV/JSON/images. Integrates with Ray Train, PyTorch, TensorFlow. Scales from single machine to 100s of nodes. Use for batch inference, data preprocessing, multi-modal data loading, or distributed ETL pipelines. skill
grpo-rl-training — Expert guidance for GRPO/RL fine-tuning with TRL for reasoning and task-specific model training skill
miles-rl-training — Provides guidance for enterprise-grade RL training using miles, a production-ready fork of slime. Use when training large MoE models with FP8/INT4, needing train-inference alignment, or requiring speculative RL for maximum throughput. skill
openrlhf-training — High-performance RLHF framework with Ray+vLLM acceleration. Use for PPO, GRPO, RLOO, DPO training of large models (7B-70B+). Built on Ray, vLLM, ZeRO-3. 2× faster than DeepSpeedChat with distributed architecture and GPU resource sharing. skill
simpo-training — Simple Preference Optimization for LLM alignment. Reference-free alternative to DPO with better performance (+6.4 points on AlpacaEval 2.0). No reference model needed, more efficient than DPO. Use for preference alignment when want simpler, faster training than DPO/PPO. skill
slime-rl-training — Provides guidance for LLM post-training with RL using slime, a Megatron+SGLang framework. Use when training GLM models, implementing custom data generation workflows, or needing tight Megatron-LM integration for RL scaling. skill
torchforge-rl-training — Provides guidance for PyTorch-native agentic RL using torchforge, Meta's library separating infra from algorithms. Use when you want clean RL abstractions, easy algorithm experimentation, or scalable training with Monarch and TorchTitan. skill
fine-tuning-with-trl — Fine-tune LLMs using reinforcement learning with TRL - SFT for instruction tuning, DPO for preference alignment, PPO/GRPO for reward optimization, and reward model training. Use when need RLHF, align model with preferences, or train from human feedback. Works with HuggingFace Transformers. skill
verl-rl-training — Provides guidance for training LLMs with reinforcement learning using verl (Volcano Engine RL). Use when implementing RLHF, GRPO, PPO, or other RL algorithms for LLM post-training at scale with flexible infrastructure backends. skill
constitutional-ai — Anthropic's method for training harmless AI through self-improvement. Two-phase approach - supervised learning with self-critique/revision, then RLAIF (RL from AI Feedback). Use for safety alignment, reducing harmful outputs without human labels. Powers Claude's safety system. skill
llamaguard — Meta's 7-8B specialized moderation model for LLM input/output filtering. 6 safety categories - violence/hate, sexual content, weapons, substances, self-harm, criminal planning. 94-95% accuracy. Deploy with vLLM, HuggingFace, Sagemaker. Integrates with NeMo Guardrails. skill
nemo-guardrails — NVIDIA's runtime safety framework for LLM applications. Features jailbreak detection, input/output validation, fact-checking, hallucination detection, PII filtering, toxicity detection. Uses Colang 2.0 DSL for programmable rails. Production-ready, runs on T4 GPU. skill
prompt-guard — Meta's 86M prompt injection and jailbreak detector. Filters malicious prompts and third-party data for LLM apps. 99%+ TPR, <1% FPR. Fast (<2ms GPU). Multilingual (8 languages). Deploy with HuggingFace or batch processing for RAG security. skill
huggingface-accelerate — Simplest distributed training API. 4 lines to add distributed support to any PyTorch script. Unified API for DeepSpeed/FSDP/Megatron/DDP. Automatic device placement, mixed precision (FP16/BF16/FP8). Interactive config, single launch command. HuggingFace ecosystem standard. skill
deepspeed — Expert guidance for distributed training with DeepSpeed - ZeRO optimization stages, pipeline parallelism, FP16/BF16/FP8, 1-bit Adam, sparse attention skill
training-llms-megatron — Trains large language models (2B-462B parameters) using NVIDIA Megatron-Core with advanced parallelism strategies. Use when training models >1B parameters, need maximum GPU efficiency (47% MFU on H100), or require tensor/pipeline/sequence/context/expert parallelism. Production-ready framework used for Nemotron, LLaMA, DeepSeek. skill
pytorch-fsdp2 — Adds PyTorch FSDP2 (fully_shard) to training scripts with correct init, sharding, mixed precision/offload config, and distributed checkpointing. Use when models exceed single-GPU memory or when you need DTensor-based sharding with DeviceMesh. skill
pytorch-lightning — High-level PyTorch framework with Trainer class, automatic distributed training (DDP/FSDP/DeepSpeed), callbacks system, and minimal boilerplate. Scales from laptop to supercomputer with same code. Use when you want clean training loops with built-in best practices. skill
ray-train — Distributed training orchestration across clusters. Scales PyTorch/TensorFlow/HuggingFace from laptop to 1000s of nodes. Built-in hyperparameter tuning with Ray Tune, fault tolerance, elastic scaling. Use when training massive models across multiple machines or running distributed hyperparameter sweeps. skill
lambda-labs-gpu-cloud — Reserved and on-demand GPU cloud instances for ML training and inference. Use when you need dedicated GPU instances with simple SSH access, persistent filesystems, or high-performance multi-node clusters for large-scale training. skill
modal-serverless-gpu — Serverless GPU cloud platform for running ML workloads. Use when you need on-demand GPU access without infrastructure management, deploying ML models as APIs, or running batch jobs with automatic scaling. skill
skypilot-multi-cloud-orchestration — Multi-cloud orchestration for ML workloads with automatic cost optimization. Use when you need to run training or batch jobs across multiple clouds, leverage spot instances with auto-recovery, or optimize GPU costs across providers. skill
awq-quantization — Activation-aware weight quantization for 4-bit LLM compression with 3x speedup and minimal accuracy loss. Use when deploying large models (7B-70B) on limited GPU memory, when you need faster inference than GPTQ with better accuracy preservation, or for instruction-tuned and multimodal models. MLSys 2024 Best Paper Award winner. skill
quantizing-models-bitsandbytes — Quantizes LLMs to 8-bit or 4-bit for 50-75% memory reduction with minimal accuracy loss. Use when GPU memory is limited, need to fit larger models, or want faster inference. Supports INT8, NF4, FP4 formats, QLoRA training, and 8-bit optimizers. Works with HuggingFace Transformers. skill
optimizing-attention-flash — Optimizes transformer attention with Flash Attention for 2-4x speedup and 10-20x memory reduction. Use when training/running transformers with long sequences (>512 tokens), encountering GPU memory issues with attention, or need faster inference. Supports PyTorch native SDPA, flash-attn library, H100 FP8, and sliding window attention. skill
gguf-quantization — GGUF format and llama.cpp quantization for efficient CPU/GPU inference. Use when deploying models on consumer hardware, Apple Silicon, or when needing flexible quantization from 2-8 bit without GPU requirements. skill
gptq — Post-training 4-bit quantization for LLMs with minimal accuracy loss. Use for deploying large models (70B, 405B) on consumer GPUs, when you need 4× memory reduction with <2% perplexity degradation, or for faster inference (3-4× speedup) vs FP16. Integrates with transformers and PEFT for QLoRA fine-tuning. skill
hqq-quantization — Half-Quadratic Quantization for LLMs without calibration data. Use when quantizing models to 4/3/2-bit precision without needing calibration datasets, for fast quantization workflows, or when deploying with vLLM or HuggingFace Transformers. skill
ml-training-recipes — Battle-tested PyTorch training recipes for all domains — LLMs, vision, diffusion, medical imaging, protein/drug discovery, spatial omics, genomics. Covers training loops, optimizer selection (AdamW, Muon), LR scheduling, mixed precision, debugging, and systematic experimentation. Use when training or fine-tuning neural networks, debugging loss spikes or OOM, choosing architectures, or optimizing GPU throughput. skill
evaluating-code-models — Evaluates code generation models across HumanEval, MBPP, MultiPL-E, and 15+ benchmarks with pass@k metrics. Use when benchmarking code models, comparing coding abilities, testing multi-language support, or measuring code generation quality. Industry standard from BigCode Project used by HuggingFace leaderboards. skill
evaluating-llms-harness — Evaluates LLMs across 60+ academic benchmarks (MMLU, HumanEval, GSM8K, TruthfulQA, HellaSwag). Use when benchmarking model quality, comparing models, reporting academic results, or tracking training progress. Industry standard used by EleutherAI, HuggingFace, and major labs. Supports HuggingFace, vLLM, APIs. skill
nemo-evaluator-sdk — Evaluates LLMs across 100+ benchmarks from 18+ harnesses (MMLU, HumanEval, GSM8K, safety, VLM) with multi-backend execution. Use when needing scalable evaluation on local Docker, Slurm HPC, or cloud platforms. NVIDIA's enterprise-grade platform with container-first architecture for reproducible benchmarking. skill
llama-cpp — Runs LLM inference on CPU, Apple Silicon, and consumer GPUs without NVIDIA hardware. Use for edge deployment, M1/M2/M3 Macs, AMD/Intel GPUs, or when CUDA is unavailable. Supports GGUF quantization (1.5-8 bit) for reduced memory and 4-10× speedup vs PyTorch on CPU. skill
sglang — Fast structured generation and serving for LLMs with RadixAttention prefix caching. Use for JSON/regex outputs, constrained decoding, agentic workflows with tool calls, or when you need 5× faster inference than vLLM with prefix sharing. Powers 300,000+ GPUs at xAI, AMD, NVIDIA, and LinkedIn. skill
tensorrt-llm — Optimizes LLM inference with NVIDIA TensorRT for maximum throughput and lowest latency. Use for production deployment on NVIDIA GPUs (A100/H100), when you need 10-100x faster inference than PyTorch, or for serving models with quantization (FP8/INT4), in-flight batching, and multi-GPU scaling. skill
serving-llms-vllm — Serves LLMs with high throughput using vLLM's PagedAttention and continuous batching. Use when deploying production LLM APIs, optimizing inference latency/throughput, or serving models with limited GPU memory. Supports OpenAI-compatible endpoints, quantization (GPTQ/AWQ/FP8), and tensor parallelism. skill
mlflow — Track ML experiments, manage model registry with versioning, deploy models to production, and reproduce experiments with MLflow - framework-agnostic ML lifecycle platform skill
experiment-tracking-swanlab — Provides guidance for experiment tracking with SwanLab. Use when you need open-source run tracking, local or self-hosted dashboards, and lightweight media logging for ML workflows. skill
tensorboard — Visualize training metrics, debug models with histograms, compare experiments, visualize model graphs, and profile performance with TensorBoard - Google's ML visualization toolkit skill
weights-and-biases — Track ML experiments with automatic logging, visualize training in real-time, optimize hyperparameters with sweeps, and manage model registry with W&B - collaborative MLOps platform skill
evolving-ai-agents — Provides guidance for automatically evolving and optimizing AI agents across any domain using LLM-driven evolution algorithms. Use when building self-improving agents, optimizing agent prompts and skills against benchmarks, or implementing automated agent evaluation loops. skill
autogpt-agents — Autonomous AI agent platform for building and deploying continuous agents. Use when creating visual workflow agents, deploying persistent autonomous agents, or building complex multi-step AI automation systems. skill
crewai-multi-agent — Multi-agent orchestration framework for autonomous AI collaboration. Use when building teams of specialized agents working together on complex tasks, when you need role-based agent collaboration with memory, or for production workflows requiring sequential/hierarchical execution. Built without LangChain dependencies for lean, fast execution. skill
langchain — Framework for building LLM-powered applications with agents, chains, and RAG. Supports multiple providers (OpenAI, Anthropic, Google), 500+ integrations, ReAct agents, tool calling, memory management, and vector store retrieval. Use for building chatbots, question-answering systems, autonomous agents, or RAG applications. Best for rapid prototyping and production deployments. skill
llamaindex — Data framework for building LLM applications with RAG. Specializes in document ingestion (300+ connectors), indexing, and querying. Features vector indices, query engines, agents, and multi-modal support. Use for document Q&A, chatbots, knowledge retrieval, or building RAG pipelines. Best for data-centric LLM applications. skill
chroma — Open-source embedding database for AI applications. Store embeddings and metadata, perform vector and full-text search, filter by metadata. Simple 4-function API. Scales from notebooks to production clusters. Use for semantic search, RAG applications, or document retrieval. Best for local development and open-source projects. skill
faiss — Facebook's library for efficient similarity search and clustering of dense vectors. Supports billions of vectors, GPU acceleration, and various index types (Flat, IVF, HNSW). Use for fast k-NN search, large-scale vector retrieval, or when you need pure similarity search without metadata. Best for high-performance applications. skill
pinecone — Managed vector database for production AI applications. Fully managed, auto-scaling, with hybrid search (dense + sparse), metadata filtering, and namespaces. Low latency (<100ms p95). Use for production RAG, recommendation systems, or semantic search at scale. Best for serverless, managed infrastructure. skill
qdrant-vector-search — High-performance vector similarity search engine for RAG and semantic search. Use when building production RAG systems requiring fast nearest neighbor search, hybrid search with filtering, or scalable vector storage with Rust-powered performance. skill
sentence-transformers — Framework for state-of-the-art sentence, text, and image embeddings. Provides 5000+ pre-trained models for semantic similarity, clustering, and retrieval. Supports multilingual, domain-specific, and multimodal models. Use for generating embeddings for RAG, semantic search, or similarity tasks. Best for production embedding generation. skill
dspy — Build complex AI systems with declarative programming, optimize prompts automatically, create modular RAG systems and agents with DSPy - Stanford NLP's framework for systematic LM programming skill
guidance — Control LLM output with regex and grammars, guarantee valid JSON/XML/code generation, enforce structured formats, and build multi-step workflows with Guidance - Microsoft Research's constrained generation framework skill
instructor — Extract structured data from LLM responses with Pydantic validation, retry failed extractions automatically, parse complex JSON with type safety, and stream partial results with Instructor - battle-tested structured output library skill
outlines — Guarantee valid JSON/XML/code structure during generation, use Pydantic models for type-safe outputs, support local models (Transformers, vLLM), and maximize inference speed with Outlines - dottxt.ai's structured generation library skill
langsmith-observability — LLM observability platform for tracing, evaluation, and monitoring. Use when debugging LLM applications, evaluating model outputs against datasets, monitoring production systems, or building systematic testing pipelines for AI applications. skill
phoenix-observability — Open-source AI observability platform for LLM tracing, evaluation, and monitoring. Use when debugging LLM applications with detailed traces, running evaluations on datasets, or monitoring production AI systems with real-time insights. skill
audiocraft-audio-generation — PyTorch library for audio generation including text-to-music (MusicGen) and text-to-sound (AudioGen). Use when you need to generate music from text descriptions, create sound effects, or perform melody-conditioned music generation. skill
blip-2-vision-language — Vision-language pre-training framework bridging frozen image encoders and LLMs. Use when you need image captioning, visual question answering, image-text retrieval, or multimodal chat with state-of-the-art zero-shot performance. skill
clip — OpenAI's model connecting vision and language. Enables zero-shot image classification, image-text matching, and cross-modal retrieval. Trained on 400M image-text pairs. Use for image search, content moderation, or vision-language tasks without fine-tuning. Best for general-purpose image understanding. skill
evaluating-cosmos-policy — Evaluates NVIDIA Cosmos Policy on LIBERO and RoboCasa simulation environments. Use when setting up cosmos-policy for robot manipulation evaluation, running headless GPU evaluations with EGL rendering, or profiling inference latency on cluster or local GPU machines. skill
llava — Large Language and Vision Assistant. Enables visual instruction tuning and image-based conversations. Combines CLIP vision encoder with Vicuna/LLaMA language models. Supports multi-turn image chat, visual question answering, and instruction following. Use for vision-language chatbots or image understanding tasks. Best for conversational image analysis. skill
fine-tuning-serving-openpi — Fine-tune and serve Physical Intelligence OpenPI models (pi0, pi0-fast, pi0.5) using JAX or PyTorch backends for robot policy inference across ALOHA, DROID, and LIBERO environments. Use when adapting pi0 models to custom datasets, converting JAX checkpoints to PyTorch, running policy inference servers, or debugging norm stats and GPU memory issues. skill
fine-tuning-openvla-oft — Fine-tunes and evaluates OpenVLA-OFT and OpenVLA-OFT+ policies for robot action generation with continuous action heads, LoRA adaptation, and FiLM conditioning on LIBERO simulation and ALOHA real-world setups. Use when reproducing OpenVLA-OFT paper results, training custom VLA action heads (L1 or diffusion), deploying server-client inference for ALOHA, or debugging normalization, LoRA merge, and cross-GPU issues. skill
segment-anything-model — Foundation model for image segmentation with zero-shot transfer. Use when you need to segment any object in images using points, boxes, or masks as prompts, or automatically generate all object masks in an image. skill
stable-diffusion-image-generation — State-of-the-art text-to-image generation with Stable Diffusion models via HuggingFace Diffusers. Use when generating images from text prompts, performing image-to-image translation, inpainting, or building custom diffusion pipelines. skill
whisper — OpenAI's general-purpose speech recognition model. Supports 99 languages, transcription, translation to English, and language identification. Six model sizes from tiny (39M params) to large (1550M params). Use for speech-to-text, podcast transcription, or multilingual audio processing. Best for robust, multilingual ASR. skill
knowledge-distillation — Compress large language models using knowledge distillation from teacher to student models. Use when deploying smaller models with retained performance, transferring GPT-4 capabilities to open-source models, or reducing inference costs. Covers temperature scaling, soft targets, reverse KLD, logit distillation, and MiniLLM training strategies. skill
long-context — Extend context windows of transformer models using RoPE, YaRN, ALiBi, and position interpolation techniques. Use when processing long documents (32k-128k+ tokens), extending pre-trained models beyond original context limits, or implementing efficient positional encodings. Covers rotary embeddings, attention biases, interpolation methods, and extrapolation strategies for LLMs. skill
model-merging — Merge multiple fine-tuned models using mergekit to combine capabilities without retraining. Use when creating specialized models by blending domain-specific expertise (math + coding + chat), improving performance beyond single models, or experimenting rapidly with model variants. Covers SLERP, TIES-Merging, DARE, Task Arithmetic, linear merging, and production deployment strategies. skill
model-pruning — Reduce LLM size and accelerate inference using pruning techniques like Wanda and SparseGPT. Use when compressing models without retraining, achieving 50% sparsity with minimal accuracy loss, or enabling faster inference on hardware accelerators. Covers unstructured pruning, structured pruning, N:M sparsity, magnitude pruning, and one-shot methods. skill
moe-training — Train Mixture of Experts (MoE) models using DeepSpeed or HuggingFace. Use when training large-scale models with limited compute (5× cost reduction vs dense models), implementing sparse architectures like Mixtral 8x7B or DeepSeek-V3, or scaling model capacity without proportional compute increase. Covers MoE architectures, routing mechanisms, load balancing, expert parallelism, and inference optimization. skill
speculative-decoding — Accelerate LLM inference using speculative decoding, Medusa multiple heads, and lookahead decoding techniques. Use when optimizing inference speed (1.5-3.6× speedup), reducing latency for real-time applications, or deploying models with limited compute. Covers draft models, tree-based attention, Jacobi iteration, parallel token generation, and production deployment strategies. skill
academic-plotting — Generates publication-quality figures for ML papers from research context. Given a paper section or description, extracts system components and relationships to generate architecture diagrams via Gemini. Given experiment results or data, auto-selects chart type and generates data-driven figures via matplotlib/seaborn. Use when creating any figure for a conference paper. skill
ml-paper-writing — Write publication-ready ML/AI papers for NeurIPS, ICML, ICLR, ACL, AAAI, COLM. Use when drafting papers from research repos, structuring arguments, verifying citations, or preparing camera-ready submissions. For systems venues (OSDI, NSDI, ASPLOS, SOSP), use systems-paper-writing instead. skill
presenting-conference-talks — Generates conference presentation slides (Beamer LaTeX PDF and editable PPTX) from a compiled paper with speaker notes and talk script. Use when preparing oral talks, spotlight presentations, or invited talks for ML and systems conferences. skill
systems-paper-writing — Comprehensive guide for writing systems papers targeting OSDI, SOSP, ASPLOS, NSDI, and EuroSys. Provides paragraph-level structural blueprints, writing patterns, venue-specific checklists, reviewer guidelines, LaTeX templates, and conference deadlines. Use this skill for all systems conference paper writing. skill
brainstorming-research-ideas — Guides researchers through structured ideation frameworks to discover high-impact research directions. Use when exploring new problem spaces, pivoting between projects, or seeking novel angles on existing work. skill
creative-thinking-for-research — Applies cognitive science frameworks for creative thinking to CS and AI research ideation. Use when seeking genuinely novel research directions by leveraging combinatorial creativity, analogical reasoning, constraint manipulation, and other empirically grounded creative strategies. skill
ara-compiler — Compiles any research input — PDF papers, GitHub repositories, experiment logs, code directories, or raw notes — into a complete Agent-Native Research Artifact (ARA) with cognitive layer (claims, concepts, heuristics), physical layer (configs, code stubs), exploration graph, and grounded evidence. Use when ingesting a paper or codebase into a structured, machine-executable knowledge package, building an ARA from scratch, or converting research outputs into a falsifiable, agent-traversable form. skill
ara-research-manager — Records research provenance as a post-task epilogue, scanning conversation history at the end of a coding or research session to extract decisions, experiments, dead ends, claims, heuristics, and pivots, and writing them into the ara/ directory with user-vs-AI provenance tags. Use as a session epilogue — never during execution — to maintain a faithful, auditable trace of how a research project actually evolved. skill
ara-rigor-reviewer — Performs ARA Seal Level 2 semantic epistemic review on Agent-Native Research Artifacts, scoring six dimensions (evidence relevance, falsifiability, scope calibration, argument coherence, exploration integrity, methodological rigor) and producing a constructive, severity-ranked report with a Strong Accept-to-Reject recommendation. Use after Level 1 structural validation passes, when an ARA needs an objective epistemic critique before publication or release. skill
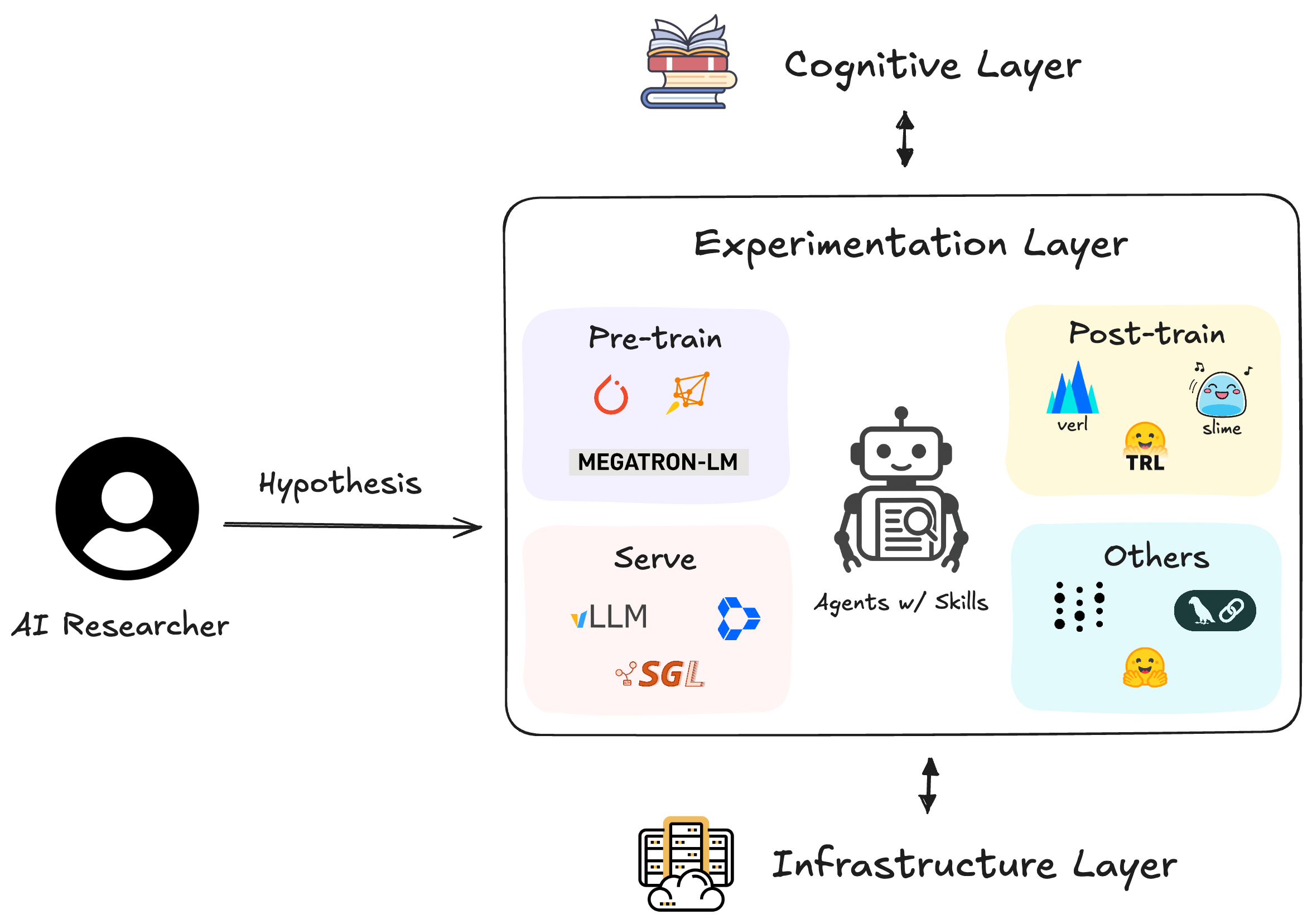
We enable AI agents to autonomously conduct AI research — from literature survey and idea generation through experiment execution to paper writing. The library provides both the research orchestration layer (autoresearch, ideation, paper writing) and the engineering skills (training, evaluation, deployment) needed at each stage.
System diagram of an AI research agent
Path Towards AI Research Agent
Modern AI research requires mastering dozens of specialized tools and frameworks.
AI Researchers spend more time debugging infrastructure than testing hypotheses — slowing the pace of scientific discovery.
We provide a comprehensive skills library that enables AI agents to autonomously conduct the full research lifecycle — from brainstorming ideas to writing the paper.
Autonomous Research - The autoresearch skill orchestrates the entire research workflow using a two-loop architecture, routing to domain skills as needed
Specialized Expertise - Each domain skill provides deep, production-ready knowledge of a specific framework (Megatron-LM, vLLM, TRL, etc.)
End-to-End Coverage - 98 skills spanning the full AI research lifecycle, from ideation and literature survey to experiments and paper writing
Research-Grade Quality - Documentation sourced from official repos, real GitHub issues, and battle-tested production workflows
Available AI Research Engineering Skills
Quality over quantity: Each skill provides comprehensive, expert-level guidance with real code examples, troubleshooting guides, and production-ready workflows.
📦 Quick Install (Recommended)
For humans — interactive installer with one command:
npx @orchestra-research/ai-research-skills
For AI agents — point your agent to the welcome doc and it handles the rest:
Read https://www.orchestra-research.com/ai-research-skills/welcome.md and follow the instructions to install and use AI Research Skills.
This installs all 98 skills, loads the autoresearch orchestration layer, and starts autonomous research.
MoE, Model Merging, Long Context, Speculative Decoding, Distillation, Pruning
Agent-Native Research Artifact
3
ARA Compiler, Research Manager, Rigor Reviewer
View All 98 Skills in Details
🔬 Autoresearch (1 skill) — Central Orchestration Layer
Autoresearch - Autonomous research orchestration using a two-loop architecture (inner optimization + outer synthesis). Manages the full lifecycle from literature survey to paper writing, routing to all domain-specific skills. Supports Claude Code /loop and OpenClaw heartbeat for continuous operation (390 lines + 3 refs)
🏗️ Model Architecture (5 skills)
LitGPT - Lightning AI's 20+ clean LLM implementations with production training recipes (462 lines + 4 refs)
Mamba - State-space models with O(n) complexity, 5× faster than Transformers (253 lines + 3 refs)
RWKV - RNN+Transformer hybrid, infinite context, Linux Foundation project (253 lines + 3 refs)
NanoGPT - Educational GPT in ~300 lines by Karpathy (283 lines + 3 refs)
TorchTitan - PyTorch-native distributed training for Llama 3.1 with 4D parallelism
Knowledge Distillation - Compress models 70B→7B with MiniLLM, temperature scaling (424 lines)
Model Pruning - 50% sparsity with Wanda, SparseGPT, <1% accuracy loss (417 lines)
📝 ML Paper Writing (2 skills)
ML Paper Writing - Write publication-ready papers for NeurIPS, ICML, ICLR, ACL, AAAI, COLM with LaTeX templates, citation verification, and writing best practices (532 lines + 5 refs)
Academic Plotting - Generate publication-quality figures for ML papers: architecture diagrams via Gemini AI and data-driven charts via matplotlib/seaborn with venue-specific styling (479 lines + 3 refs)
💡 Ideation (2 skills)
Research Brainstorming - Structured ideation frameworks for discovering high-impact research directions with 10 complementary lenses (384 lines)
Creative Thinking - Cognitive science frameworks (bisociation, structure-mapping, constraint manipulation) for genuinely novel research ideas (366 lines)
🧬 Agent-Native Research Artifact (3 skills)
ARA Compiler - Compiles any research input (PDF papers, repos, experiment logs, raw notes) into a complete Agent-Native Research Artifact with claims, exploration graph, evidence, and code stubs (245 lines + 3 refs)
ARA Research Manager - Post-task research recorder that runs at session end to extract decisions, experiments, dead ends, and pivots from conversation history into the ara/ directory with user-vs-AI provenance tags (324 lines + 3 refs)
ARA Rigor Reviewer - ARA Seal Level 2 semantic epistemic review scoring six dimensions of research rigor (evidence relevance, falsifiability, scope, coherence, exploration integrity, methodology) with severity-ranked findings (322 lines + 1 ref)
Demos
All 87 skills in this repo are automatically synced to Orchestra Research, where you can add them to your projects with one click and use them with AI research agents.
Generate publication-quality figures for the Andes QoE-aware LLM serving paper — Gemini AI architecture diagrams + matplotlib data charts (CDF, multi-panel grids, bar charts)
Featured Demos: Two papers produced entirely by AI agents using the autoresearch skill. The Norm Heterogeneity paper demonstrates autonomous research pivoting — the agent refuted its own hypothesis and discovered a stronger finding. The RL Brain Scan paper demonstrates multi-skill orchestration — the agent trained RL models, analyzed internals with interpretability tools, and synthesized the insight that "DPO is rank-1 alignment." Both papers written end-to-end by the agent.
Skill Structure
Each skill follows a battle-tested format for maximum usefulness:
skill-name/
├── SKILL.md # Quick reference (50-150 lines)
│ ├── Metadata (name, description, version)
│ ├── When to use this skill
│ ├── Quick patterns & examples
│ └── Links to references
│
├── references/ # Deep documentation (300KB+)
│ ├── README.md # From GitHub/official docs
│ ├── api.md # API reference
│ ├── tutorials.md # Step-by-step guides
│ ├── issues.md # Real GitHub issues & solutions
│ ├── releases.md # Version history & breaking changes
│ └── file_structure.md # Codebase navigation
│
├── scripts/ # Helper scripts (optional)
└── assets/ # Templates & examples (optional)
Quality Standards
300KB+ documentation from official sources
Real GitHub issues & solutions (when available)
Code examples with language detection
Version history & breaking changes
Links to official docs
Roadmap
We're building towards 80 comprehensive skills across the full AI research lifecycle. See our detailed roadmap for the complete development plan.
Architecture, Tokenization, Fine-Tuning, Mechanistic Interpretability, Data Processing, Post-Training, Safety, Distributed, Optimization, Evaluation, Infrastructure, Inference, Agents, RAG, Multimodal, Prompt Engineering, MLOps, Observability, ML Paper Writing, Ideation, Autoresearch
Full Lifecycle ✅
Recent Progress: npm package @orchestra-research/ai-research-skills for one-command installation across all coding agents
Philosophy: Quality > Quantity. Following Anthropic official best practices - each skill provides 200-500 lines of focused, actionable guidance with progressive disclosure.
Open Source AI Community - For amazing tools and docs
Special thanks to:
EleutherAI, HuggingFace, NVIDIA, Lightning AI, Meta AI, Anthropic
All researchers who maintain excellent documentation
Contributors
Thanks to all the people who have contributed to the AI Research Skills Library:
We welcome contributions from the AI research community! See CONTRIBUTING.md for detailed guidelines on:
Adding new skills
Improving existing skills
Quality standards and best practices
Submission process
Recent Updates
April 2026 - v1.6.0 🧬 Agent-Native Research Artifact (ARA) — 23rd Category, 98 Skills
🧬 NEW CATEGORY: 22-agent-native-research-artifact/ (the 23rd category) — three skills that turn research outputs into a falsifiable, agent-traversable artifact:
🛠️ ARA Compiler — compiles any input (PDF papers, GitHub repos, experiment logs, raw notes) into a structured ARA with cognitive layer (claims, concepts, heuristics), physical layer (configs, code stubs), exploration graph (research DAG), and grounded evidence
📋 ARA Research Manager — post-task epilogue that scans conversation history at session end and writes decisions, experiments, dead ends, claims, heuristics, and pivots into the ara/ directory with user / ai-suggested / ai-executed / user-revised provenance tags
🔍 ARA Rigor Reviewer — Seal Level 2 semantic epistemic review scoring six dimensions of research rigor (evidence relevance, falsifiability, scope calibration, argument coherence, exploration integrity, methodological rigor) and emitting a severity-ranked report with a Strong Accept-to-Reject recommendation
🔗 Sourced from the Agent-Native-Research-Artifact-Init reference repo, restructured to AI-research-SKILLs standards (kebab-case names, third-person descriptions, Title-Case tags, one-level-deep references)
🧩 Plugin entry agent-native-research-artifact added to .claude-plugin/marketplace.json; CLI category registered as 22-agent-native-research-artifact with three individual skill entries in the npm installer
🔄 Auto-syncs to Orchestra marketplace via sync-skills.yml on push; npm package republished as @orchestra-research/ai-research-skills@1.6.0 via publish-npm.yml on version bump
📊 98 total skills across 23 categories — full lifecycle from idea → paper → falsifiable, auditable artifact
March 2026 - v1.4.0 🔬 Autoresearch & 86 Skills — Full Research Lifecycle
🔬 NEW SKILL: Autoresearch — autonomous research orchestration using a two-loop architecture (inner optimization loop + outer synthesis loop)
🧠 Manages the full research lifecycle: literature survey → ideation → experiments → synthesis → paper writing
🔄 Routes to all 86 domain skills automatically — agents don't need to know which skill to use
⏰ Mandatory /loop (Claude Code) and cron job (OpenClaw) for continuous autonomous operation
📊 Generates research presentations (HTML/PDF) with optimization trajectory plots for human review
📝 Findings.md as persistent project memory across sessions with "Lessons and Constraints" tracking
📝 9,617 new lines of documentation across 30 files
32 total skills (45% towards 70-skill target)
November 6, 2025 - v0.2.0
Added 10 skills from GitHub (Megatron-Core, Lightning, Ray Train, etc.)
Improved skill structure with comprehensive references
Created strategic roadmap to 70 skills
Added contribution guidelines
November 3, 2025 - v0.1.0
🎉 Initial release with 5 fine-tuning skills
Community
Join our community to stay updated, ask questions, and connect with other AI researchers:
SkillEvolve Meta-Skill - Connect your agent to the collective intelligence of the community. Captures techniques discovered during sessions and shares them back as curated skills.